
Entity resolution with a MIO solution: An explainer
Entity resolution is essential to almost any strategy for getting meaningful insight and use from your data. And while the basic concept is relatively straightforward, implementing it can be considerably more complex.
Over time, your data will change and evolve. Your entity resolution needs to be equally dynamic.
MIO-built entity resolution, using our MIOvantage data platform, is exactly that. To meet your operational and analytical needs over time, MIO's entity resolution has:
- A business-oriented model
- Raw data as fragmentary representations of entities
- Clustering and transitive matching
- A sophisticated synthesis process to make complex decisions
- Fragment-based provenance of an entity even after it's resolved
- Relationship discovery between entities, even when these relationships are only implied
- Architecture that activates data only as it's needed, reducing performance-limiting factors
Our entity resolution is maintainable over time, high-performance for real-time entity resolution activities, and retains a detailed data lineage.
In this article, we’ll explore the technical underpinnings of entity resolution the MIO way.
Representing Entities: Modeling
MIOsoft's entity resolution is driven by a central business model. Unlike traditional data models, our model is highly flexible and can leverage industry-, domain-, and company-specific knowledge.
A key differentiator: our model uses a business-driven perspective of the entities. Its primary lens is the business, not the physical or logistical structure of a data storage system. This often results in a multi-entity, multi-domain model.
The model defines first-order concepts about the entities that you're interested in. In addition to the base data about the entities that you already have, this also can include computations like profitability, favorite locations, historical buying patterns, or upsell opportunities.
This is possible because our business model derives from the idea of the object model, and has many of the same properties, including logic, polymorphism, and hierarchical composition.
Model boundaries
The model also represents information about the relationships between entities. These are established by what we call context boundaries.
Context boundaries are the one aspect of our modeling for entity resolution that has technical considerations: while business needs should be a major factor in the placing context boundaries, they also have an important role in determining how your data is partitioned and stored, which has performance ramifications.
Representing Data: Fragments
Fragments
As data arrives, a MIOsoft solution breaks it down into pieces that are relevant at the entity level using the model.
In most scenarios, a single piece of data—generally, when data is incoming initially, this "piece" is a single record from a single system—contains only a part of the information that the business knows about an entity.
We use each record to fill out the model to the extent possible. This partial instantiation of the model is what we call a fragment.
Our solution does not restrict how complete or incomplete a fragment must be on a technical level.
From a practical perspective, a fragment needs to include a certain level of detail in order to be useful. Generally, sources that cannot consistently provide fragments with enough information are identified and ruled out during data preparation.
EXAMPLE
Telecom Inc.'s incoming data contains fragments A and B, which both represent a customer.
There is some overlapping information in the fragments:
- Social Security Number
- Date of Birth
- First Name
- Middle Name
- Last Name
But each fragment also contains information which the other fragment does not contain.
Sample Fragments for Telecom Inc
In these example fragments, looking at the overlapping data suggests that these fragments could represent the same person, since they share a SSN, last name, and first and middle initials.
Depending on the context in which you are using the data, this may be an acceptable amount of evidence. In other situations, you may need additional information in order to consider the two fragments to be about the same person.
This is the type of deduction and decision-making that we encode in the system: having a person review each fragment pair is not feasible, and human review will have imperfect consistency of decision-making. Automated decision-making, on the other hand, is scalable, consistent, and reviewable.
Finding Entities: Clustering
As data volumes increase, it becomes impossible to maintain a strategy of comparing each fragment for potential matches with every other fragment while also maintaining an acceptable level of performance.
To avoid this, our solutions sort fragments into smaller pools as soon as they enter the system. Fragments within these pools are then grouped together with other fragments that are likely to match each other.
This "likelihood" is defined on a per-project basis, by selecting the piece(s) of data used for fragment pool sorting.
The item or combination of items that defines the fragment pools is called the fragment index. Each pool is made up of fragments which have identical fragment index values.
As each fragment is indexed and added to the pool, the pool retains a copy of the fragment in its current state. The pool retains this copy even after the fragment has passed further into the entity resolution process.
Once in the pool, the fragments in the pool are clustered, identifying which fragments are actually about the same entity. Clustering is approximately equivalent with matching in match-merge-link terminology.
The resulting clusters are groups of fragments that are about the same entity; each group (cluster) is then passed through the entity resolution process. There's no limit on the size of a fragment group; it could contain hundreds of fragments, dozens, or just one.
The entity is constructed by considering all of the fragments in the cluster.
Using a fragment pool reduces the amount of comparison processing needed to establish clusters, which allows a MIOsoft solution to maintain the speeds needed for high-performance high-volume entity resolution.
Technical discussion: Index value selection
Selecting values for the fragment index is partly driven by the business perspective of the entities: what data is both valuable and available for identifying an entity, and what isn't.
We also consider your performance needs for the solution: more closely the fragment pools correspond to actual entities, the better the solution will perform. The more important high performance is, the more important it is to select an effective fragment index.
However, even for a well-selected fragment index, it's possible that at some point a disproportionately large fragment pool will be created. Often, though not always, this happens because one of the pieces of data included in the index has a default value in a large segment of records.
The too-large fragment pool can impact performance. To combat this, we can specify a maximum pool size. Any fragment pool that exceeds this size will be dissolved, and the index value that was used to create the pool will no longer be considered a valid index value, for existing or for incoming fragments. The index will continue to work normally for all other values that occur for the index.
Fragment Clustering
In production systems—i.e., in circumstances that involve real data—it's rare to find a one-size-fits-all approach that works to create effective fragment clusters. The wide variety in fragments and the different ways that matches can be identified necessitates an entity resolution solution that can use many different strategies.
Our entity resolution solutions make this possible by using unsupervised machine learning to permit fragment matching based on a wide variety of functions.
Fragment matching in MIOsoft solutions can be based on individual pieces of data, using:
- Equality functions
- Domain-specific heuristics
- Distance functions, including:
- Full-word similarity
- Partial-word similarity
- Typographical errors
- Structural differences
- Phonetic similarities
- Arbitrary selection
Concrete examples of matching function types that are commonly employed in our solutions are shown in Table 1. These functions are specified at the level of individual pieces of data within fragments, allowing very complex definitions of how two fragments are allowed to match.
Sample Cluster Function Types
| Function Type | Allows matching |
|---|---|
| Ignore | To ignore elements such as special characters and leading or trailing 0s. |
| Phonetic | Based on phonetic similarity using algorithms such as Soundex, Cologne, Phonix, Metaphone, QGram, and more. |
| Substring | Based on similar substrings, prefixes, or postfixes. |
| Error | To take place even with a certain amount of typographical errors, transpositions, or errors per characters or tokens. |
| Numeric | Based on closeness of numeric values or other arithmetic functions. |
| Data-Specific | Based on known reference data. |
| Data-Type-Specific | Based on data-type specific functions, such as temporal or geospatial proximity. |
EXAMPLE (CONT.)
In the current example scenario, Telecom Inc. decides that for any two fragments similar to A and B in structure, the fragments can be considered to match if their SSNs are identical and their names are very similar, or if the SSNs differ by one typographical error and all name fields are identical.
In practice there is almost always more than one way in which two fragments can be considered a match to each other. To accommodate this, our solutions express match rules as matrices.
A rule matrix is a group of individual rules.
Each individual rule represents a different way in which two fragments should be allowed to match. For fragments to match by a rule, all of the rule's conditions must be true for the fragment pair.
The matrix as a whole represents that the match should be allowed at all. If fragments match by at least one of the rules within a matrix, they are considered to match by the matrix as a whole.
In other words, a match takes place if the boolean AND of all conditions for a rule are true, for any rule (boolean OR) in the matrix.
EXAMPLE
Shown below is an example cluster matrix for Telecom Inc.
Rule 1 Rule 2 Rule 3 Rule 4 Social Security Number Equal Equal Equal 1 Typo Date of Birth Equal Equal First Name First Initial First Initial Equal Equal Middle Name First Initial Equal Last Name Phonetic Similarity 2 Typos
In actual deployments, cluster matrices can be much more extensive and complex than shown in this basic example.
Cluster rule implementation in our solutions supports these more involved rules in multiple ways, including:
- Support for distance functions that use multiple attributes, including those needed for comparing spatial data.
- Specifying cluster matrices hierarchically, in alignment with the hierarchy of the business model. This allows the cluster matrix that is specified for a subordinate object to, itself, be used as a cluster function in a superordinate object's rules.
Transitive Matching
We use a transitive match strategy to do clustering, which allows our solutions to have much more nuance than direct-match-only strategies do.
With transitive matching, fragments are considered to match each other—and therefore, can belong to the same cluster—under the following circumstances:
- The fragments match each other directly, according to the match rules.
- The fragments mutually match with a third fragment.
- The fragments are linked by a chain of directly-matching fragments.
Transitive matching allows, theoretically, for two fragments to match even if they have no data whatsoever in common. In practice, fragments which match will often have something in common, although in the absence of the other fragments this commonality would not be definitive.
Transitive matching is particularly useful in cases where fragments originate from sources which have very different purposes, and therefore have relatively little data in common even though they are about the same entity.
Transitive matching is also useful in scenarios involving spatial data, like geographical events. Any two given events may have occurred too far apart to be considered directly related. However, an event at an intermediate point might make a relationship between those distant points more probable; events at multiple intermediate points make it even more so.
Finally, transitive matching also plays an important role in making entity resolution possible long-term. Because fragment matching in our solutions is available even for resolved entities, transitive matching can be used to combine and split existing resolved entities as new fragments bring additional information about the entity or entities.
Building Entities: Synthesis
An entity will usually be created using data from more than one fragment, although our solutions don’t require this.
The more important to the business an entity is, the more likely it is that multiple systems know about the entity, creating a multi-fragment cluster. However, even comparatively minor entities are often created from multiple fragments.
Multi-fragment entities introduce the possibility that fragments which are about the same entity can have conflicting data about that entity.
There can be a variety of underlying reasons for these conflicts. Common ones include:
- Entry errors, such as typographical errors
- Outdated information, such the name of a business which has since been absorbed by a competitor
- Factual changes, such as a person's name change or new address
- Data provision conflicts, such as when a person gives different (valid) email addresses at different times
- Purposeful provision of incorrect data
When these conflicts are present, they must be resolved (so that a consistent entity can be available for analytics, operations, and other uses), and/or identified (so that the source of the conflicts can be addressed).
After matching fragments, our solutions use a process called synthesis to determine the resolved picture of the entity.
Synthesis resolves conflicts between two or more values by examining not just the values themselves, but their metadata and the sources they originated from. Synthesis is approximately equivalent to merging in match-merge-link technology.
The values selected by the synthesis rules are used to populate the final representation of the entity. Generally, it is this resolved entity that is made available to end users, applications, and databases.
Note that our solutions don’t have any built-in requirement for all of the selected values to come from the same fragment(s) or from any particular number or combination of fragments.
Synthesis rule definition
Our solutions use highly-customized synthesis rule definitions: in our experience, default rules for synthesis have limited utility, which decreases as the significance of the data increases.
Metadata that synthesis rules can evaluate includes:
- The magnitude of the value.
- The source system from which the value originated.
- The recency of the fragment from which the value originated.
- The frequency of the value's occurrence, among all occurring values for the attribute.
Although the synthesis process produces a resolved entity, our solutions also retain the original, pre-synthesis fragments. These are maintained and accessible as long as the entity exists in the solution.
Typically, fragments are only accessed directly for non-operational purposes like validating the entity resolution process. However, the fragment data can be used instead of or in addition to the resolved entity data operationally, if needed.
Entity Provenance
Even after an entity has been resolved, our solution maintains all of the original fragments that were used to create it, even those that did not contribute any data to the resolved entity.
This allows us to maintain the provenance of a cluster and its associated entity. This is primarily leveraged in two major ways: entity re-evaluation, and entity investigation.
Entity re-evaluation
Consider two fragments which do not match directly, and do not have any mutual matches between them. These fragments would belong to distinct entities in one of our solutions.
However, operational systems routinely have new data enter the system.
New fragments, when combined with the existing fragments, may create a mutual match (or chain of matches) between fragments that previously had no connection. This new match indicates that two (or more) previously-formed entities are actually the same entity.
This can only work if all of the original fragments are still there, since some or all of a fragment’s data might not be retained to the final entity at the end of the resolution process.
If one of those originally-unused fragments is essential to the new match, discarding it precludes the ability to ever make that new match. This places significant limitations on the ability to re-evaluate entities: data from any system that is added after the initial matching takes place is less useful.
Our solutions do retain all original fragments and always work from the fragment level, so new data can be continually evaluated in context with all prior fragments. Any data contributed to the system can fully contribute to entity resolution, no matter when it is added.
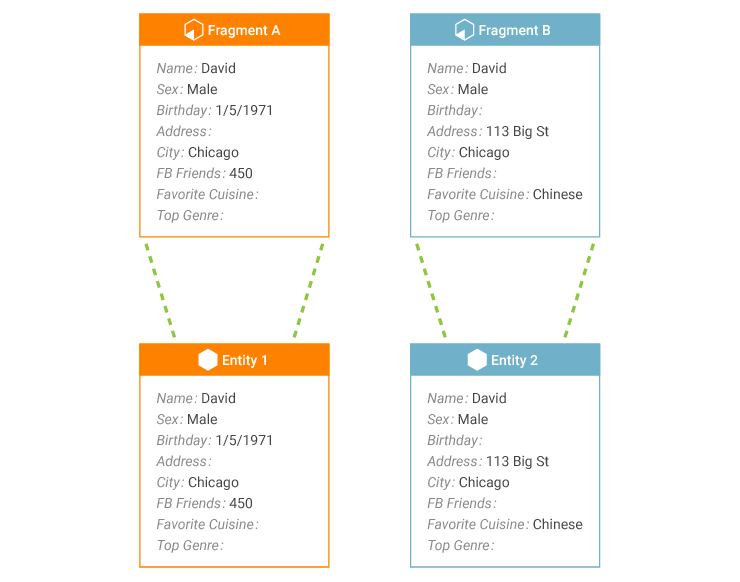
For example, consider a pair of fragments A and B. When these fragments first enter a MIOsoft entity resolution solution, there is no direct or mutual match between them, so they are placed in separate clusters.
This creates separate entities, Entity 1 and Entity 2, based off of the clusters containing fragments A and B. The entities are then made available for operational use.
Later, a new fragment C enters the system. This fragment matches both A and B.
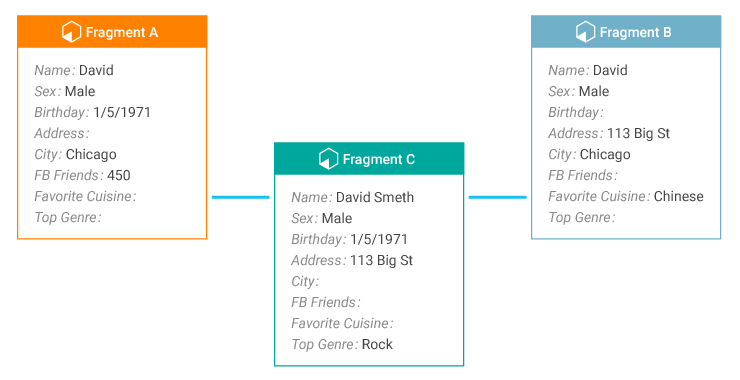
When this match is made, Entity 1 and Entity 2 needs to be re-evaluated.
Fragments A, C, and B now belong to the same cluster (match group). The cluster is passed through the synthesis process, resulting in Entity 3.
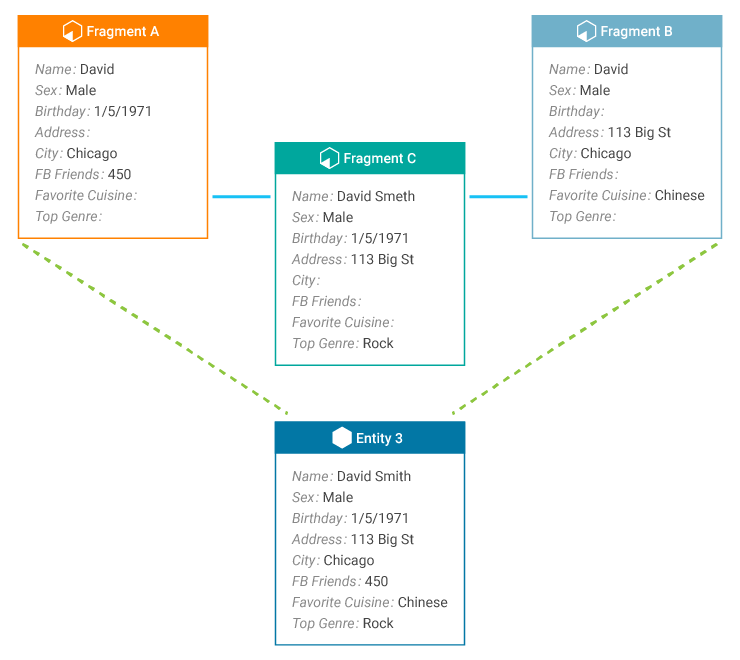
Entities 1 and 2 are removed, and Entity 3 created. This process is relatively efficient because our solution maintains the previously-created data structures.
Although this example illustrates the essential behavior of what is taking place during entity resolution, note that in practice it would be common for the linked entities to be resolved from multiple fragments each. It is also possible for more than two entities to be re-evaluated as a single fragment group.
Entity investigation
Since our solutions retain the original fragments that were used to create an entity, these fragments can be retrieved and examined even while the resolved entity is also being used operationally.
This allows the entity resolution process to be investigated and analyzed long-term, not just during initial development. Fragment access post-synthesis can be used for purposes like continuous improvement, error correction, and root cause analysis.
These types of long-term improvement are only possible when the original fragments remain accessible; if only the resolved entities are retained, data is technically lost at every step.
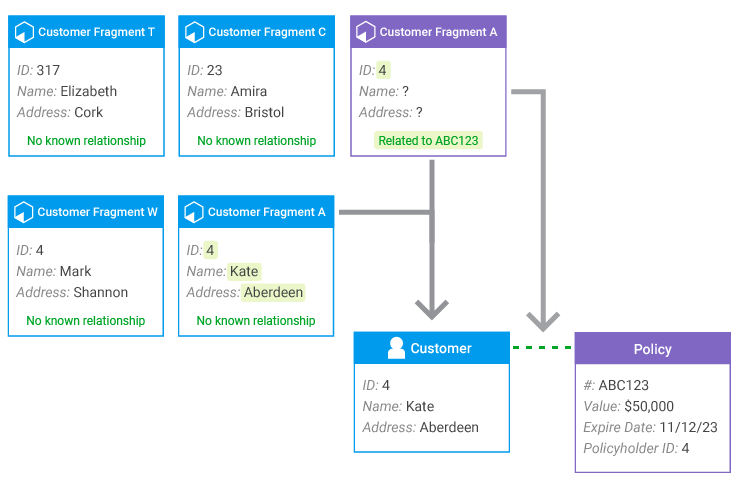
For example, consider a situation in which a customer service representative enters a person's name as "Cate."
This fragment then goes through the entity resolution process.
If the existing entity—which matches the fragment in every other respect—spells the name "Kate," and no other information is retained, incorporating the new fragment into the entity is not well-informed: is the entity name misspelled, or is the new fragment's name misspelled?
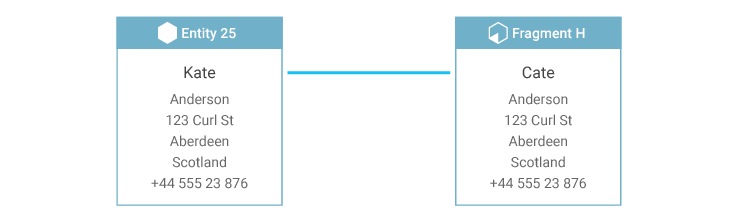
But if the fragments behind the existing entity are retained, there can be additional evidence regarding which value is correct, or possibly evidence that the correct value is not known.
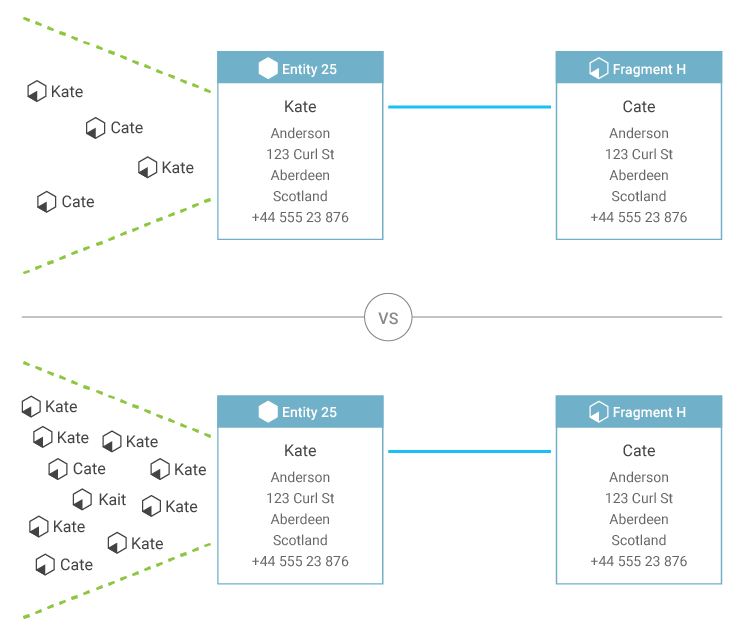
Consider a situation where fragments used to create the existing entity are evenly split between "Cate" and "Kate." Depending on the solution configuration, the entity can be flagged because the name choice cannot be made confidently, or synthesis rules may use an alternate form of decision-making where value frequency is not decisive.
For instance, in the top Entity 25 of the diagram, "Kate" could be selected because the fragment that was created earliest used "Kate," or because a generally-trustworthy system used "Kate," because "Kate" is more common than "Cate," or perhaps "Kate" was simply selected arbitrarily.
But consider a situation where the majority of the fragments use the name "Kate," with occasional fragments that use other spellings. In this situation, it's possible to be relatively confident that the new fragment contains the misspelling, and that the entity should retain the spelling "Kate." This same logic would hold no matter which spelling was most common, allowing for occasional data entry errors without constantly changing the entity's resolved name.
This kind of assessment is only possible when all fragments are retained.
Connecting Entities: Relationships
Once an entity exists, its own data may suggest potential relationships that it could have with other entities.
For instance, a customer of an insurer has a relationship to the policy that they hold. They also have a relationship to the beneficiaries of that policy, and a relationship to address where they live. If other customers live at that same address, or insure property at that address, the original customer is likely to have a familial or social relationship with those other customers.
This type of relationship can be represented in our solutions, then automatically identified and created during synthesis. This relationship discovery is approximately equivalent with linking in match-merge-link terminology.
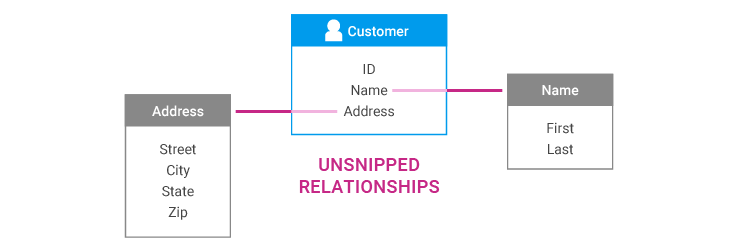
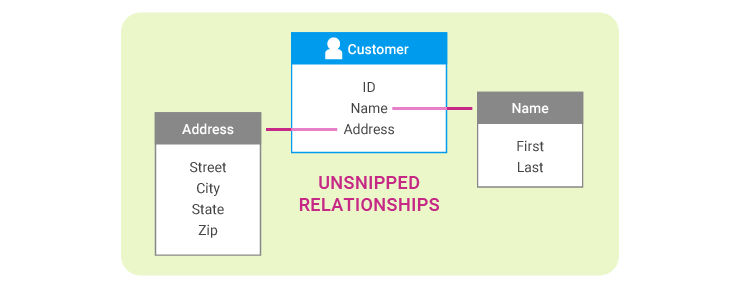
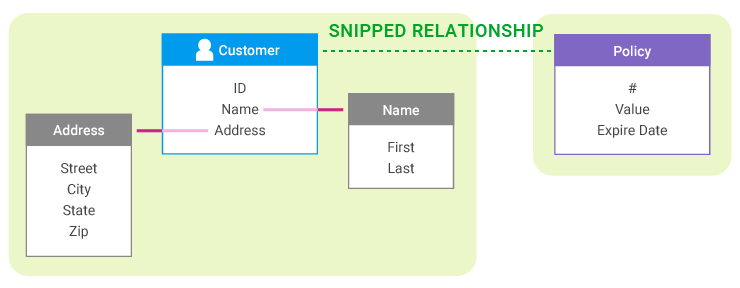
Our model uses an explicit relationship modeling approach. Entity relationships can be categorized as either "snipped" or "unsnipped."
An "unsnipped" relationship means that the two entities, as defined in the model, should be considered as one entity from a business perspective. Essentially, an unsnipped relationship is an intra-entity relationship.
For example, for various reasons, the model may represent a personal name as an entity with an unsnipped relationship to a customer entity. There are reasons to make this distinction in the model, but those distinctions are not important from the perspective of the resolved "customer" entity.
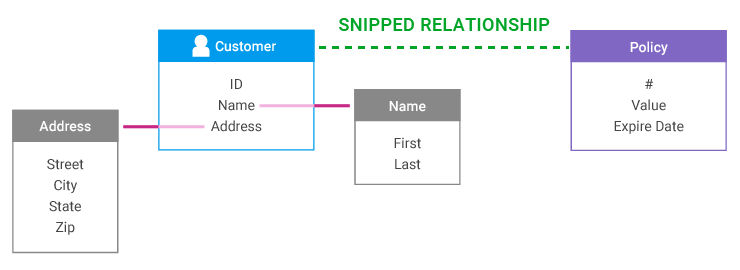
A "snipped" relationship means that the two entities, as defined in the model, should not be considered as one entity. A snipped relationship is an inter-entity relationship.
This is the kind of relationship that a customer has to a policy, or a customer to a residence; the two entities are connected, but from a business perspective they are not one.
In other words, a snipped relationship is a context boundary, as introduced in the modeling discussion.
Our solution’s process for automatically discovering snipped relationships between different entities is particularly powerful because it can use the fragment clustering mechanisms to identify and create these relationships even when they are not explicitly denoted in the data.
One of these primary mechanisms is the data that identifies a potential relationship with another entity. This data is used to create a special fragment of that other entity's type, called a grappling fragment.
The grappling fragment maintains a reference to the entity that created it, but then undergoes the normal clustering process for an entity of its type.
Once the grappling fragment has been clustered and resolved into an entity, that entity will "grapple" back to its source entity. This creates the snipped relationship, which is immediately visible to both entities.
With a snipped relationship established, each entity can push summary data about itself to the other entity. This allows both entities to have immediate, up-to-date access to the most critical information about the entity, without manual data denormalization, and while maintaining the performance benefits of our approach to entity storage.
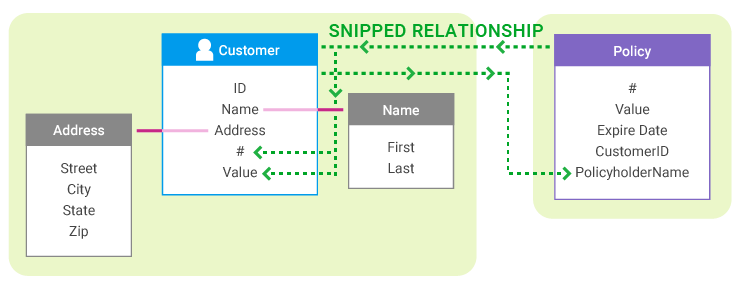
As an example of grappling, consider a Policy. In addition to the policyholder, who is a known Customer, the policy also has a beneficiary.
A MIOsoft solution can recognize the name (and any other information about the beneficiary that is known) as potential Customer* information. Therefore, in addition to the Policy fragment, each record of a policy also generates grapple Customer fragments for the policyholder and the beneficiary.
If the beneficiary of the policy is also a customer, with their own accounts, the beneficiary grapple fragment will be clustered with the beneficiary's other fragments. We can now connect the policyholder with the beneficiary, even if the only place where their information appears together is on the record of the policy.
This also means that second- (and more) degree connections can be identified in our solutions: for example, the policyholder now has a relationship with the beneficiaries of the original beneficiary's other policies. This is particularly useful for applications of entity resolution such as fraud detection.
* To better accommodate the business reality of situations like this, actual implementations may use a "Person" entity instead, which recognizes customers, beneficiaries, etc. under its umbrella and allows individuals to hold multiple roles. The example relationship models shown, like all those discussed here, have been simplified for illustrative purposes.
Consider a situation in which separate systems hold Policy and Customer information. A policy record has the customer ID number of the policyholder, but a customer record does not have any information about a person's policies.
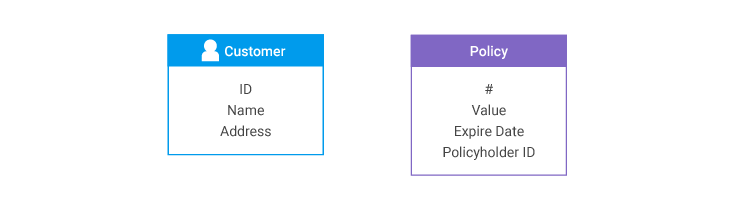
In the model, there is a snipped relationship between Customer and Policy entities.
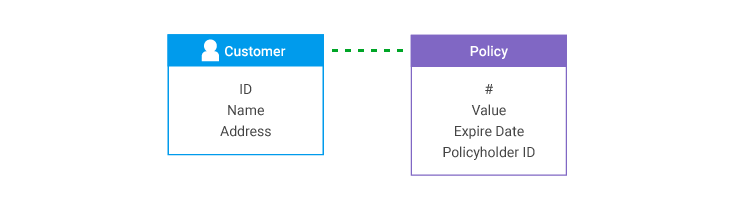
When records are loaded from the Customer system, there is no way to connect any of them during entity resolution to any Policy records that might exist, except that every Policy has created a Customer grapple fragment from its Policyholder ID.
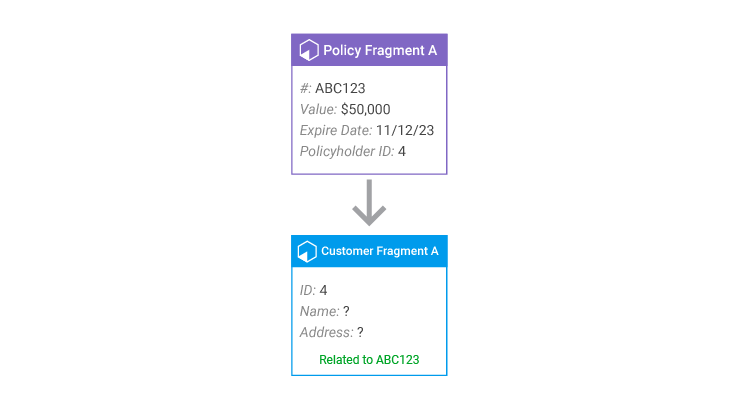
While the Policyholder ID is the only data that the grapple fragment has, it's enough to match the grapple fragment to another Customer fragment. When entity resolution for Customers takes place, the grapple fragment is incorporated into a Customer entity and contributes its knowledge of the relationship to a specific policy to the final Customer entity, so this relationship can be represented in the data.
In this example, it was simple to match the Customer fragments for illustrative purposes. With real-life data, which often does not have reliable (or any) keys, the grapple fragment is essential for building the inter-entity relationships, since it cannot be replicated with a lookup.
Ongoing Use of Entities
Performance
Performance and data volume
A key benefit of our solutions is that their entity resolution performance is independent of the amount of existing data and the number of existing resolved entities.
Instead, our entity resolution performance is related to the amount of incoming data.
This is the case because, when a new fragment is received, it undergoes the normal indexing and clustering process. But only the fragment groups to which new fragments are actually added continue with the entity resolution process. The fragment groups which are unchanged, and the associated entities, do not change state.
Consider the example entity re-evaluation scenario. When fragment C entered the system, fragments A and B, and entities 1 and 2, were activated as a result.
But any operational enterprise would also have many other fragments and entities present in the system at the same time.
These fragments and entities were not activated by the entry and matching of fragment C, so they remained dormant.
This behavior is critical to our solution’s scalability. Not only does it ensure that the amount of processing needed for entity resolution is independent of the amount of stored data, but it allows effective work with data sources where data creation and updates are frequent.
Consider, for instance, streaming, transaction queue, and sensor data sources. These sources can generate large amounts of new and updated data on a continual basis.
If all data is activated during the entity resolution process, performance has two limiting factors: the amount of incoming data and the amount of existing data. With our approach, performance faces only one limiter: the amount of incoming data.
The re-evaluation and retrieval process is efficient because we store all data that belongs to the same entity together on the disk, as described in Representing Entities: Modeling. As a result, while the database as a whole can be highly distributed, each individual entity's data is not.
Storing all data about an entity together significantly reduces search and retrieval time when compared to a strategy that distributes an entity across multiple storage locations.
As a result of the entity-based storage approach, we can take advantage of the speed of in-memory computing and the economy of disk-based storage at the same time. The value of this is particularly evident at the petabyte-plus scale, where in-memory storage is impractical with current technology.
Performance and model boundaries
For purposes of storing and re-activating entities, entities that have unsnipped relationships with each other are considered to be one entity. Thus, in the example unsnipped relationship shown previously, the Customer entity would include, and be stored with, the Name and Address entities.
The presence of a snipped relationship indicates separate entities. Thus, again considering the previous example, the Policy entity is not automatically retrieved or updated just because the Customer entity was.
Since the snipped relationships and context boundaries determine the size of entities, placement of the context boundaries needs to balance two competing factors:
- The size of the entity: The larger an entity, the longer it takes to retrieve and update it
- The data that needs to be associated with that entity for actual use: The more entities have to be fetched in order to carry out routine operational or analytical activities, the longer it takes to retrieve and update them
When placing context boundaries, the factors are balanced along with your performance needs. Under-snipping can create entities that are too large for the solution to be performant; over-snipping can create a situation where the number of entities required to do anything also reduces performance.
Our solution alleviates some of the compromises required for this by allowing summary information to be pushed across snipped relationships. This summary is designed to contain the most commonly-needed information about the entity, so that the related entity can know this information without having to retrieve the entire entity.
For example, in the previous Customer-Policy unsnipped relationship, the policy's number and value might be pushed to the Customer. The customer's policy numbers and their values can then be known while looking at the Customer entity without retrieving the corresponding Policy entities.
This summary data remains current because updates (if any) are automatically pushed to all extant summaries whenever the originating entity is updated.
Summary
The basic tenets of entity resolution are relatively straightforward. But when you closely examine the actual implementation needs for entity resolution in terms of operations, analytics, and performance, you reveal more complex issues.
Our entity resolution solutions are designed to allow flexible, multi-entity and multi-domain entity resolution, using a business model. This also allows the entity resolution to discover relationships between entities, even when these relationships are not explicitly identified in the data.
Our solution is high-performance as data arrives, regardless of whether the data is creating new entities or updating existing entities. By maintaining the lineage of the entities with their original fragments, our entity resolution also delivers maximum meaning over time.
As a result, MIOsoft’s entity resolution is both high-performance and high-quality, making it ideally suited for a wide range of applications.
With our experienced team to design and implement, it’s easy to get an entity resolution solution that’s tailored to you. To get started, contact us today.